
Decision Tree Learning is a popular method for classification and regression tasks, but it comes with several challenges and issues:
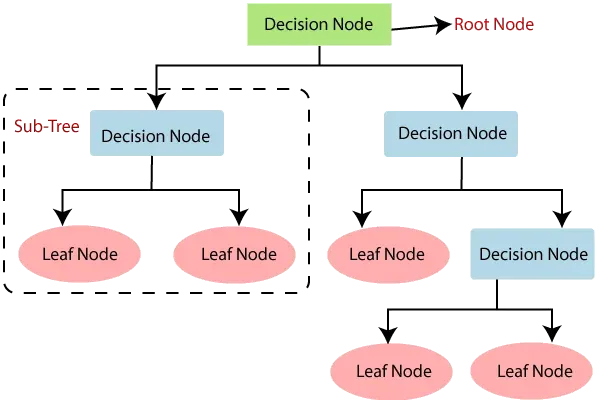
-
Overfitting: Decision trees are prone to overfitting, especially when they are deep or complex. They may capture noise in the training data, leading to poor generalization on unseen data. Pruning techniques and limiting tree depth help mitigate this.
-
Bias Toward Features with More Categories: Decision trees tend to favor features with more categories or unique values. For instance, categorical features with many distinct values may dominate the tree construction, even if they aren't the most informative.
-
Instability: Small changes in the training data can lead to large changes in the structure of the decision tree, making them unstable. This sensitivity can affect the model's reliability and robustness.
-
Handling of Missing Values: Decision trees can struggle with missing data. Although methods exist to handle missing values, they often require additional preprocessing or imputation, which can complicate model building.
-
Complexity: A decision tree can become overly complex with large datasets or many features, making it difficult to interpret. While shallow trees are easier to understand, they may not capture all relevant patterns.
-
Non-linearity: Decision trees can struggle to model complex, non-linear relationships unless they are combined with other methods like random forests or boosting techniques.
These challenges highlight the need for careful tuning and preprocessing to create effective decision tree models.

0 Comments